在人工智能的浪潮中,卷積神經網絡(CNN)無疑是計算機視覺領域的基石技術之一。作為一名喜歡在技術領域“打醬油”但深度關注底層演進的老鳥,我深感從經典的LeNet到現代的EfficientNet,這不僅僅是網絡層數的堆疊或參數量的增加,更是一場關于模型架構、計算效率與泛化能力的深刻革命。本文旨在梳理這一發展脈絡,并探討其對人工智能基礎軟件開發帶來的啟示。
1. 開山鼻祖:LeNet-5(1998)
LeNet-5由Yann LeCun等人提出,是第一個成功應用于手寫數字識別的CNN。其結構簡潔明了:卷積層、池化層、全連接層的順序堆疊,確立了CNN的基本范式——局部連接、權值共享和下采樣。它雖然小巧,但證明了通過卷積自動提取分層特征的有效性,為后續研究指明了方向。在軟件開發中,LeNet的實現往往是初學者理解CNN運作原理的最佳起點。
2. 深度崛起:AlexNet(2012)與VGGNet(2014)
AlexNet在ImageNet競賽中一戰成名,真正點燃了深度學習的熱潮。它引入了ReLU激活函數、Dropout正則化和GPU加速訓練等關鍵技術,證明了深度(8層)網絡強大的表征能力。緊隨其后的VGGNet則通過反復堆疊3x3的小卷積核,構建了16-19層的均勻網絡,強調了“深度”的重要性。這一時期,基礎軟件開發開始面臨挑戰:如何高效管理更深的網絡、利用并行計算資源以及防止過擬合。框架如Caffe、TensorFlow的興起,正是為了應對這些復雜性。
3. 結構創新:Inception(GoogLeNet,2014)與ResNet(2015)
隨著網絡加深,模型退化(并非過擬合導致的性能飽和)和計算成本成為瓶頸。GoogLeNet的Inception模塊通過并行使用不同尺寸的卷積核(1x1, 3x3, 5x5)和池化,在增加網絡寬度的同時控制了參數量,其核心思想是“密集計算結構替代稀疏結構”。而ResNet的革命性在于提出了殘差學習,通過快捷連接(shortcut)實現了超深度網絡(如152層)的成功訓練,解決了梯度消失/爆炸問題,使“深度”幾乎不再受限。這兩者標志著CNN設計從簡單的堆疊轉向了精心設計的模塊化架構。對軟件開發而言,這意味著需要支持更靈活的網絡拓撲和復雜的層間連接。
4. 輕量化與自動化:MobileNet(2017)與EfficientNet(2019)
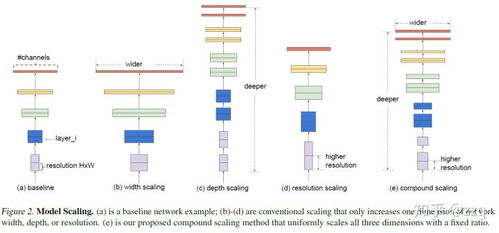
將CNN部署到移動端和嵌入式設備催生了輕量化模型的需求。MobileNet系列利用深度可分離卷積大幅降低了計算量和參數量,在精度和效率間取得了出色平衡。而EfficientNet則將架構搜索推向了新高度。它系統地研究了網絡寬度(channel數)、深度(層數)和分辨率(輸入圖像尺寸)的縮放關系,并提出復合縮放方法,使用神經架構搜索(NAS)找到了最優的縮放系數基線模型(B0-B7)。EfficientNet在同等計算資源下,實現了前所未有的精度提升,代表了當前CNN在精度-效率權衡上的前沿。
對人工智能基礎軟件開發的啟示
作為“打醬油的老鳥”,我觀察這一演進過程,對軟件開發有幾點深刻體會:
- 抽象與模塊化:從LeNet的硬編碼到Inception/ResNet的模塊化設計,軟件框架必須提供高級API,讓開發者能像搭積木一樣構建復雜網絡。
- 計算圖優化:隨著結構變得復雜(如殘差連接),框架后端需要強大的計算圖優化能力,以實現高效的內存利用和算子融合。
- 硬件協同:從AlexNet的GPU加速到MobileNet的移動端部署,軟件棧必須考慮跨平臺、跨硬件的性能移植,支持專用加速器(如NPU)。
- 自動化工具集成:EfficientNet的成功離不開NAS。未來的開發平臺可能需要將架構搜索、超參調優等自動化工具無縫集成到工作流中,降低專家門檻。
- 從研究到生產的管道:模型演進速度極快,軟件需要支持從原型(研究)到部署(生產)的平滑過渡,包括模型壓縮、量化和轉換工具。
****
從LeNet到EfficientNet,CNN的發展是一部追求“更優性能”與“更高效率”的編年史。它不僅是學術思想的碰撞,也深刻驅動著人工智能基礎軟件的革新。對于開發者和研究者而言,理解這條脈絡,不僅能更好地應用現有模型,更能洞察下一個可能的技術突破點。在這個過程中,即使是“打醬油”,也能在關注底層演進中,為構建更強大、更易用的AI工具鏈貢獻一份力量。